-
[C언어/자료구조] 연결리스트(Linked list) 개념 (인프런)CS/자료구조&알고리즘 2020. 1. 16. 15:23
※ 인프런 무료강좌 C로 배우는 자료구조(권오흠 교수님)를 보고 개인적인 복습을 위해 정리한 내용입니다.
List와 Set
List (리스트)
순서 O
(1, 2, 3) =/= (3, 2, 1)
Set (집합)
순서 X
{1, 2, 3} = {3, 2, 1}
리스트 (List)
리스트를 구현하는 대표적인 두 가지 방법은 배열, 연결리스트가 있다.
삽입(insert), 삭제(remove), 검색(search) 등 기본적인 연산이 가능하다.
배열 vs 연결리스트
배열
크기가 고정되어있어 reallocation이 필요하다.
리스트의 중간에 원소를 삽입하거나 삭제할 경우 다수의 데이터를 옮겨야 한다.
랜덤 액세스 가능.
연결리스트
길이 제한 x
다른 데이터의 이동없이 중간에 삽입이나 삭제 가능.
랜덤 액세스 불가능.
랜덤 액세스
배열은 첫번째 원소의 주소값을 담은 포인터이고,
배열의 모든 칸에는 같은 타입의 데이터가 들어가기 때문에 모든 칸의 크기가 같다.
그렇기 때문에 만약 n번째 칸의 주소를 알고 싶다면,
( 배열의 시작주소 + 한 칸의 크기 * n-1 ) 과 같은 간단한 연산으로
바로 알아낼 수 있다.
→ 랜덤 액세스가 가능하고, 배열의 몇번째 칸에 접근하더라도 걸리는 시간이 같다.
연결리스트는 이러한 배열의 장점인 랜덤 액세스가 불가능한 대신,
길이를 변경할 수 있고
중간에 데이터를 삽입하거나 삭제하더라도 다른 데이터를 이동시키지 않아도 된다.
연결리스트(Linked List)란
배열은 메모리의 연속된 공간에 데이터를 저장하고 그 데이터들의 순서관계를 유지하는 구조이다.
연결리스트는 데이터를 반드시 순서대로 저장하지 않아도, 순서관계를 표현할 수가 있다.
한 데이터를 저장하면, 다음으로 저장된 데이터의 주소가 같이 저장되기 때문이다.
다음으로 저장된 데이터가 없을 경우 NULL이 같이 저장된다.
첫번째 데이터 + 두번째 데이터의 주소(108)
두번째 데이터 + 세번쩨 데이터의 주소(103)
세번째 데이터 + 네번째 데이터의 주소(107)
네번째 데이터 + NULL (다섯번째 데이터가 존재하지 않음)
데이터의 삽입과 삭제
데이터가 실제 저장되는 주소가 순서대로 연속되어있는지는 중요하지 않다.
데이터에 함께 저장되는 '다음 데이터의 주소'를 통해 순서대로 연결이 되기 때문이다.
리스트의 중간에서 새로운 데이터를 삽입하고 싶다면,
이전 데이터에 같이 저장되어있는 다음 데이터의 주소만 바꿔주면 된다.
데이터를 삭제하거나 순서를 바꿀 때에도 마찬가지로 데이터에 함께 저장되어있는 주소값만 바꿔주면 된다.
배열처럼 데이터를 삽입하거나 삭제할 때마다 다수의 데이터를 옮기지 않아도 된다.
노드(Node)와 필드
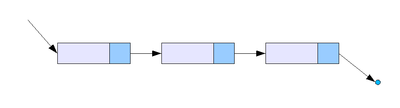
단일 연결리스트 (출처 : 위키백과) [데이터 + 다음 데이터의 주소] 한 묶음을 '노드'라고 부른다.
각각의 노드는 '데이터 필드'와 '링크 필드'로 구성되며,
링크 필드는 다음 노드의 주소를 저장한다.
연결리스트는 이렇게 여러 개의 노드들이 링크로 연결되어있는 자료구조이다.
첫번째 노드의 주소는 따로 저장해야하며, 절대 잊어버리지 말아야한다.
마지막 노드의 링크 필드에는 'NULL'을 저장하여 연결리스트의 끝임을 표시한다.
다음은 연결리스트에서 하나의 노드를 표현하기 위한 구조체이다.
각 노드에 저장될 데이터는 하나의 문자열이라고 가정했다.
struct node { char *data; /*데이터 필드 : 하나의 문자열 저장 */ struct node *next; /*링크 필드 : 다음 노드의 주소 저장 */ } typedef struct node Node; Node *head = NULL; /* 첫 번째 노드의 주소를 저장할 포인터 */포인터 변수 next는 struct node 타입의 포인터이다.
이렇게 노드 구조체는 자신과 동일한 구조체에 대한 포인터(다음 노드의 주소를 저장하는 링크 필드)를 멤버로 가진다는 의미에서 "자기참조형 구조체"라고 부르기도 한다.
typedef를 이용해 struct node 타입을 한 단어("Node")로 재정의했다.
그리고 나서 첫번째 노드의 주소를 저장할 포인터 변수인 head를 선언했다.
head는 노드의 주소값을 담기 때문에 Node(=struct node) 타입의 포인터이다.
'CS > 자료구조&알고리즘' 카테고리의 다른 글
[C언어/자료구조] 연결리스트 - 다항식 (0) 2020.01.19 [C언어/자료구조] 연결리스트(Linked list) 기본 연산 예제 (인프런) (0) 2020.01.17 [C언어/자료구조] 전화번호부 v5.0 (인프런) (0) 2020.01.14 [C언어/자료구조] 전화번호부 v4.0 (인프런) (0) 2020.01.13 [C언어/자료구조] 전화번호부 v3.0 (인프런) (0) 2020.01.12